Transformer-Based Learned Optimization
CVPR 2023
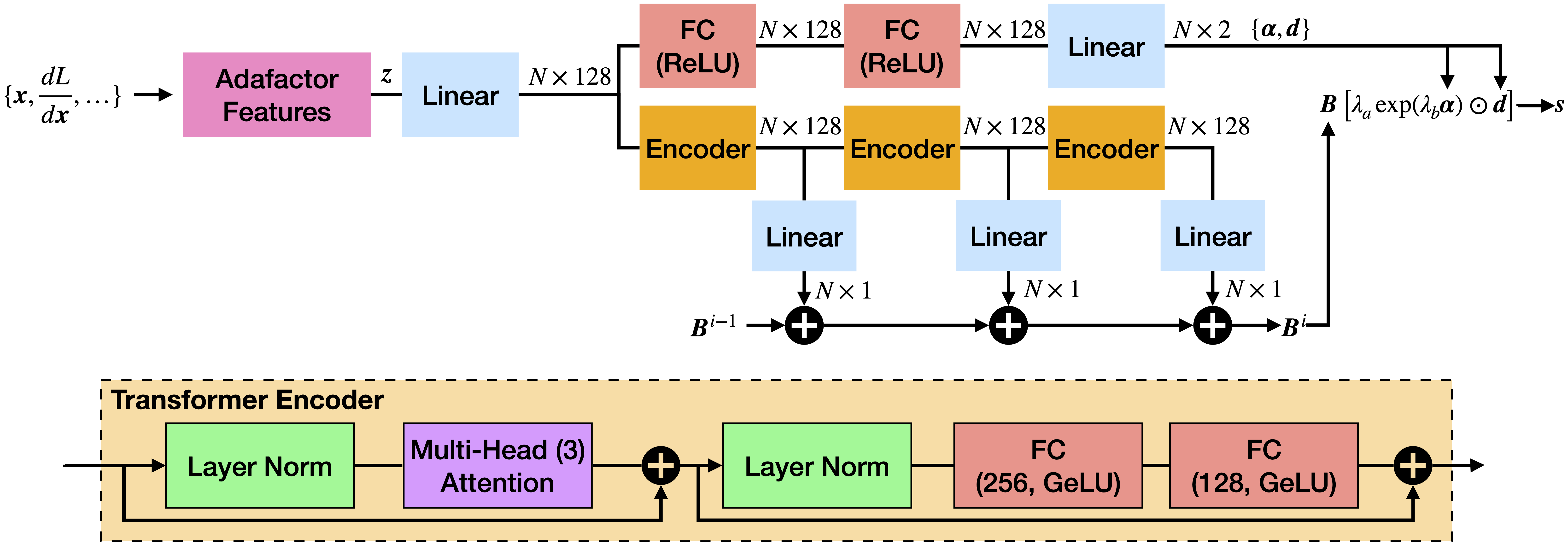
Abstract
We propose a new approach to learned optimization where we represent the computation of an optimizer's update step using a neural network. The parameters of the optimizer are then learned by training on a set of optimization tasks with the objective to perform minimization efficiently. Our innovation is a new neural network architecture, Optimus, for the learned optimizer inspired by the classic BFGS algorithm. As in BFGS, we estimate a preconditioning matrix as a sum of rank-one updates but use a Transformer-based neural network to predict these updates jointly with the step length and direction. In contrast to several recent learned optimization-based approaches, our formulation allows for conditioning across the dimensions of the parameter space of the target problem while remaining applicable to optimization tasks of variable dimensionality without retraining. We demonstrate the advantages of our approach on a benchmark composed of objective functions traditionally used for the evaluation of optimization algorithms, as well as on the real world-task of physics-based visual reconstruction of articulated 3d human motion.
Video
Citation
@inproceedings{gartner2023optimus,
title={Transformer-Based Learned Optimization},
author={Gärtner, Erik and Metz, Luke and Andriluka, Mykhaylo and Freeman, C. Daniel and Sminchisescu, Cristian},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
year={2023}
}